重要
这篇文章是我看完《Neural Networks and Deep Learning》一书后的个人读书笔记。本文的风格更加偏向于对有一定数学基础的人的科普,并非专业文章。如果你是相关专业的学生或者专业人士,在学习和研究过程中应该考虑研读权威书籍,请勿以本文作为参考。如有理解错误,欢迎指正。
本文主要围绕着如何识别手写数字展开。具体来讲就是给定一个28x28的纯灰度图的手写数字图像,如何判断它是0-9中的哪个数字。我们将使用一个简单的神经网络来实现这个功能。
output={01if ∑jwjxj≤thresholdif ∑jwjxj>threshold
如图,我们有三个输入x1、x2、x3(0或1),分别对应权重w1、w2、w3。它们的线性组合经过一个激活函数后输出一个结果output(0或1)。
我们令 z=w1x1+w2x2+w3x3,如果 z≤threshold,则 output=0;如果 z>threshold,则 output=1。这里threshold是我们给定的一个阈值。
这就是一个感知器。
举个例子,比如今天我想去某个地方玩,我正在决定是否要去。我到底去不去,取决于以下三种因素:
- 今天天气如何,1代表晴,0代表下雨
- 目的地离地铁近不近,1代表近,0代表远
- 有没有人一起去,1代表有,0代表无
然后我给这三种因素分别赋予一个权重:
- 假设我并不是很在意天气,令w1=2
- 假设我也并不介意离地铁站距离,令w2=2
- 假设我很关心有没有人一起去,令w3=6
那么,根据不同的阈值,我们可以得到不同的结果:
- 如果阈值为5,说明不管天气如何、不管距离地铁站远近,我去不去只取决于有没有人一起去。
- 如果阈值为3,说明如果天气好,我就去;如果天气不好,但是离地铁站近并且有人一起去,我也去。
接下来,我们用多个感知器组合起来,就可以形成一个感知器网络:

对于上面这个式子
output={01if ∑jwjxj≤thresholdif ∑jwjxj>threshold
我们做两个简写:
- 我们把(w1,w2,⋯,wj)看做一个向量w,(x1,x2,⋯,xj)看做一个向量x。它们一一对应相乘后求和,可以用向量的点乘表示w⋅x
- 我们把threshold移项到左边来,用b=−threshold代替它
这样,我们可以写成下面这种漂亮的形式
output={01if w⋅x+b≤0if w⋅x+b>0
我们来讨论一种特殊的感知器:
- 输入x1=1、x2=1,则w⋅x+b=−2−2+3<0,输出0
- 输入x1=1、x2=0,则w⋅x+b=−2+3>0,输出1
- 输入x1=0、x2=1,则w⋅x+b=−2+3>0,输出1
- 输入x1=0、x2=0,则w⋅x+b=3>0,输出1
当且仅当x1和x2都为1时,最终输出才为0,这就是经典的与非门。既然有了与非门,那么我们很容易就能得到加法器,这里就不展开介绍了。
我们有这样一个好消息:因为计算机就是由一个一个与非门搭建起来的,所以只要我们搭建足够大的感知器网络,就能使它和其他计算设备一样强大。
但坏消息是:它看上去只不过是一种新的与非门。
不过还有一个好消息是:我们可以设计一个算法,来自动调整权重w和偏置b。这就是所谓的学习算法。
如果w或者b产生微小的改变,会引起output的微小改变,我们就可以通过微调,使输出变得越来越好,这个过程就是学习的过程。
但是前面的感知器并不可以,因为当结果跨过阈值的时候,输出会发生突变。我们要想个办法平滑这种突变。
我们进行一个微小的改动,我们允许0到1之间的任何值作为输入,并且令:
output=σ(z)≡1+e−z1
其中z=w⋅x+b。这个就叫做sigmoid function,函数图像如下:
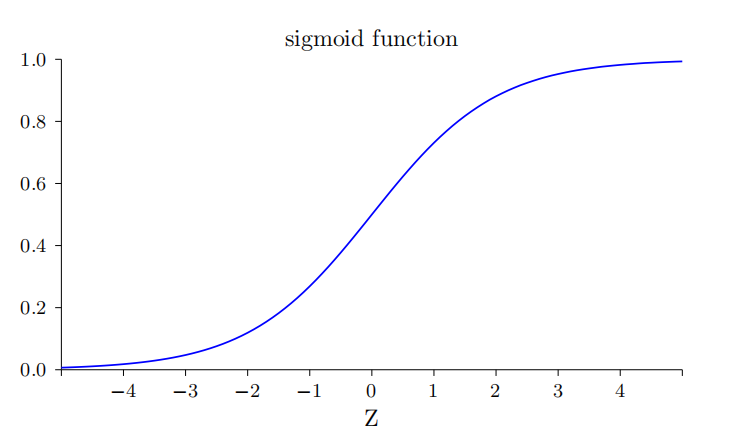
这样一来,我们用光滑的曲线代替了阈值threshold的突变,同时也将输出output限制在了0和1之间。
接下来,我们要重新定义一下神经网络:
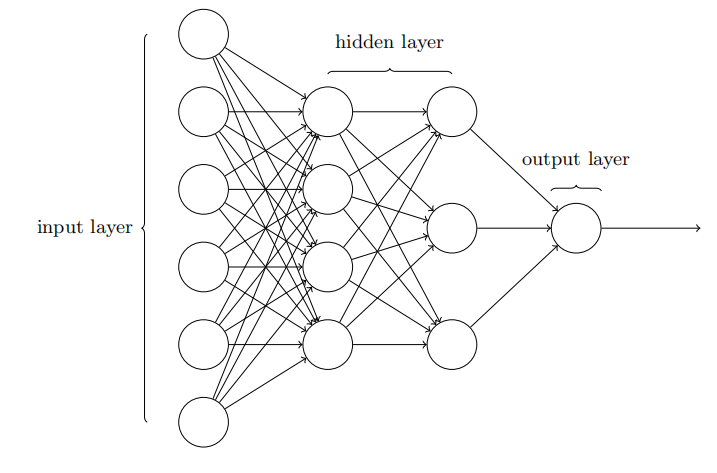
其中,最左边一列叫做输入层,最右边一列叫做输出层,中间的叫做隐藏层。每一层的每一个节点都和下一层的每一个节点相连,这个就叫做全连接。
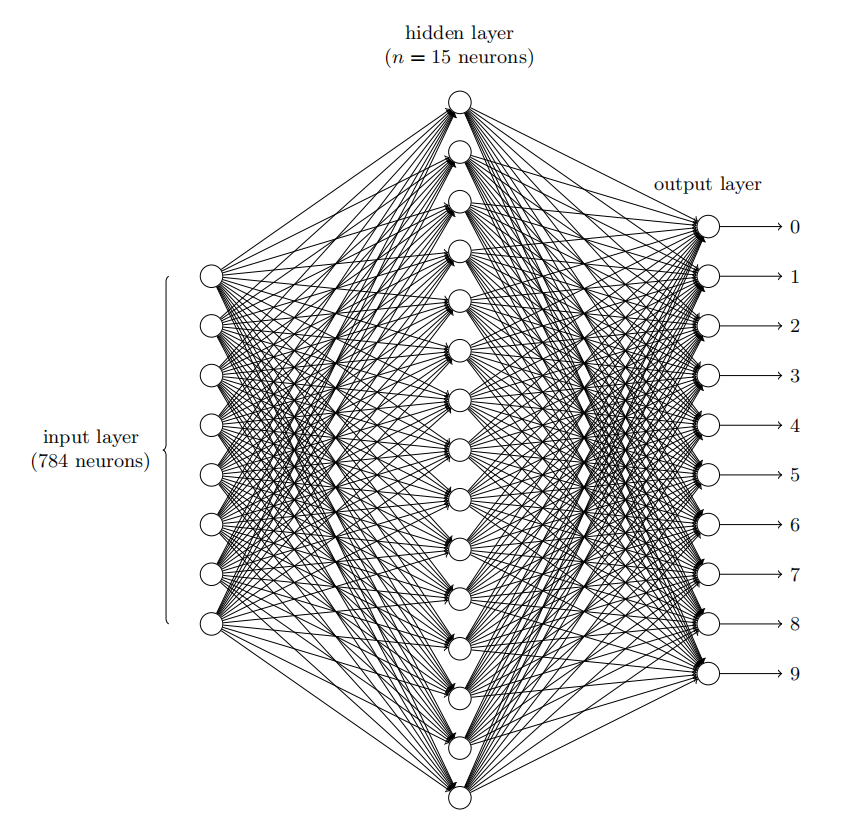
我们的每个数字都是大小为28×28=784个像素的灰度图像,我们将它展平为一个784维的向量x。我们将每个像素点的灰度值(0-255)除以255,变成0-1之间的数值,其中0.0代表白色,1.0代表黑色。
一共有0-9十个输出,每个输出的值可以视为“是这个数字的可能性”,我们简单地把输出值最大(“可能性最大”)的那个输出作为对应判断的数字。
注意
这里说的“可能性”并不是数学意义上的“概率”,只是我为了方便理解而做的一个比喻。
MNIST 数据分为两个部分。第一部分包含 60000 幅用于训练数据的图像。这些图像扫描自 250 人的手写样本。这些图像是 28×28 大小的灰度图像。第二部分是 10000 幅用于测试数据的图像,同样是 28×28 的灰度图像。我们将用这些测试数据来评估我们的神经网络学会识别数字有多好。为了让其有好的测试表现,测试数据取自和原始训练数据不同的另外一组 250 人。这有助于确保我们的系统能识别那些没有看到训练数据的人写的数字。
我们首先给w和b的每个分量填上均值为0、方差为1的随机数。
对于训练集的数据,输入和输出都是已知的,例如这个数字是 6 ,对应的 0-9 的输出应该是 (0,0,0,0,0,0,1,0,0,0) 。根据输入的数据,我们带入计算,也可以得到一个输出。这两个输出之间会存在一个误差。
我们用这样一个函数来描述误差的大小:
C(w,b)≡2n1x∑∣∣y(x)−a∣∣2
这个就叫做代价函数。代价函数是误差的体现。
我们的目的是调整w和b,使代价函数最小。
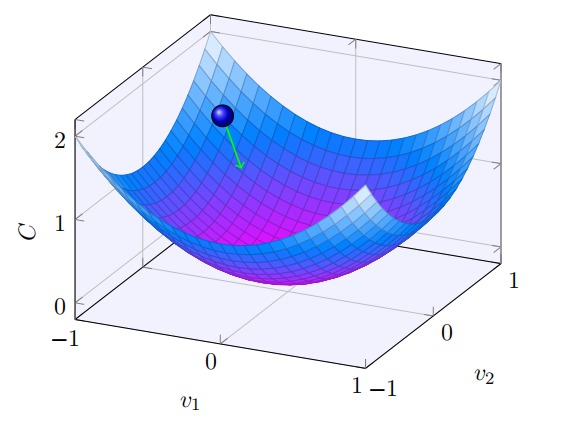
我们知道,只要沿着梯度的方向移动,就可以使C减小。
对于二维的v=(v1,v2),我们有:
ΔC∇CΔCΔvv→v′=∂v1∂CΔv1+∂v2∂CΔv2=(∂v1∂C,∂v2∂C)T≈∇C⋅Δv=−η∇C=v−η∇C
对于多维的v=(v1,v2,⋯,vn),上述公式同样有效。
有了这个公式,我们就可以很容易得到每一层的每一个w和b的值了:
v→v′wk→wk′bk→bk′=v−η∇C=wk−η∂wk∂C=bk−η∂bk∂C
这样一来,我们的目标就变成了,求出代价函数C对wk和bl的偏导数。
先做一个简单的定义:
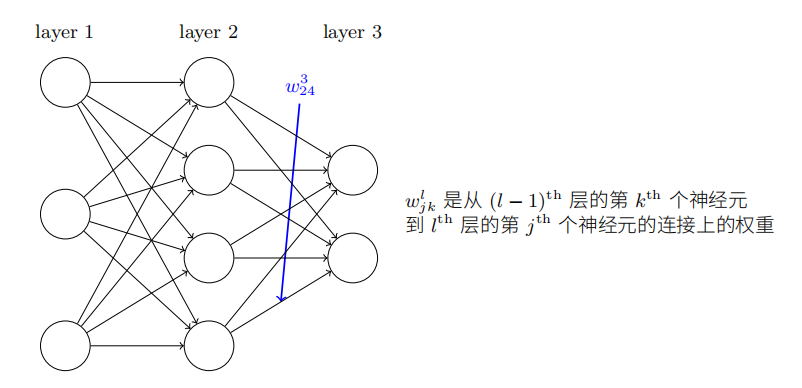
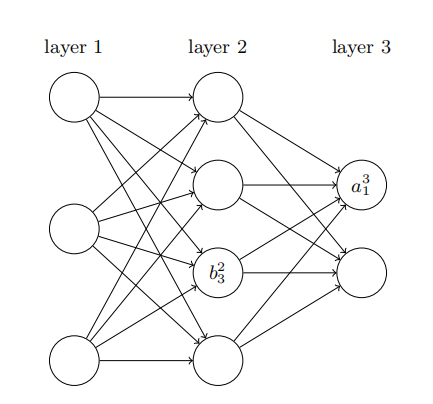
bjl表示第l层第j个神经元的偏置,ajl表示第l层第j个神经元的激活值(经过sigmoid function之前的值)。
推到过程较为复杂,这里省略,直接给出结论。
- 首先正向推导,得出输出层误差δ
- 下一层的误差推倒当前层的误差:δl=((wl+1)Tδl+1)⊙δ′(zl)
- 求出代价函数的梯度:∂wjkl∂C=akl−1δjl 和 ∂bjl∂C=δjl
- 沿梯度方向按照某一个步长更新权重和偏置
为此,我用 Java 实现了这样一个识别手写数字的逻辑:https://github.com/CuteReimu/MNIST-Template
注意
这个实现是纯手写的,只为检验我对算法的理解。如果真的想要学习神经网络,建议使用 TensorFlow、PyTorch 等深度学习框架。
